



p값의 배신 : p값은 과연 진리인가
 1000
충남대학교병원 성형외과 권혁재
1000
충남대학교병원 성형외과 권혁재
권혁재 선생님은 한국과학기술원(KAIST) 전산학과 졸업 후 충남대학교 의학전문대학원을 수료하고 현재 충남대학교병원 성형외과에서 전임의로 근무하고 있습니다. 대한의료정보학회가 주최하고 한국정보의학 인증의관리위원회가 주관하는 정보의학인증의 (certified physician in biomedical informatics) 교육 수련 과정을 수료하면서 정보의학의 개론에서부터 파이썬, R과 같은 프로그래밍, 인공지능, 빅데이터, 바이오 유전체 정보학, 디지털 헬스케어 전반에 이르기까지 다양한 내용을 공부하였습니다. 이번 칼럼을 통해 논문을 작성할 때 흔히 활용하는 p-value에 대해 되짚어보고자 합니다.

아래 대화는 어떤 대학원의 석사과정생 둘의 대화이다.
“어쩌지? 통계 돌렸더니 p값이 다 0.05를 넘어서 쓸 게 없어. 이 주제는 논문으로 쓰긴 좀 그렇겠다. 졸업할 수 있을까?”
“걱정마. 내가 도와줄게. 정리한 데이터 좀 보여줄래?”
아래의 대답을 한 석사과정생은 과연 어떤 생각이 있는 것일까? 그 이야기를 한번 해보고자 한다. 의학에서 어떤 치료가 기존 치료방법보다 더 효과가 좋다는 주장을 하기 위해서는 무언가 근거가 있어야 한다. 이러한 근거로서 가장 많이 사용되는 통계학적 도구가 바로 p-value가 아닐까 싶다. 많은 논문들이 “p값이 0.05미만이므로 통계학적으로 유의하다. 그러므로 이 치료/중재는 효과가 있다.”라는 식의 결론을 내린다.
이 p값이란게 정말 절대적인 값일까?
간단히 이야기하면 p값은 그 일이 “우연히 일어날” 확률이다. 어떤 일이 우연히 일어날 확률이 5%미만일때 통상적으로 유의하다고 해석하고 있다. 그런데 이 p값이 모두를 속일 수 있다면?
p값을 이용한 가설검정방식은 영국의 통계학자 로널드 피셔(Ronald Aylmer Fisher, 1890~1962)경이 제안하고 널리 보급하였다. 하지만 그 당시 피셔 경의 생각으로는 0.05라는 값이 어떤 가설의 참과 거짓을 가르는 절대적인 기준이 아니었다. 그저 말 그대로 가설과 데이터가 얼마나 일치하는지 보여주는 수치였을 뿐이다. 그러나 언제부터인가 많은 사람들이 p<0.05를 절대적인 진리인 것처럼 쓰고 말하고 있다. 그러다 보니 여러가지 문제점이 발생하게 된다.
다음 그래프를 살펴보자.

2012년에 3617개의 논문을 분석해서 p값을 수집해서 정리한 그래프이다(1). 일반적으로 균등분포 한다고 알려져 있는 p값이 0.05미만에서 기대빈도보다 급격히 증가하는 것을 볼 수 있다. 어째서 이런 일이 발생하는 것일까? 첫 번째로는 유의하지 않으면 publish 되기 어려워 publication bias가 발생하기 때문이고 두 번째로는 p값이 0.05보다 커서 유의하지 않을 경우 연구자의 가설이 기각되어 가설이 틀렸다는 결론이 나오게 되므로 연구자가 다양한 방법으로 가설을 지지하는 방향으로 데이터의 해석을 하려고 노력하기 때문이다. 이러한 결과는 다른 논문에서도 비슷하게 살펴 볼 수 있는데 아래 그림을 보자.
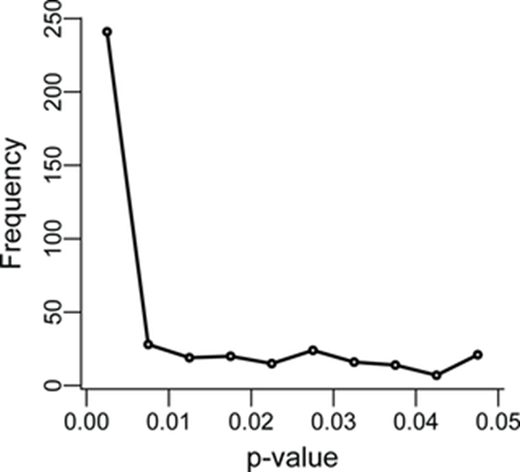
그래프상 p값들이 0.05보다 살짝 작은 값에 다소 집중되어있는 것을 볼 수 있는데 연구진들의 분석에 따르면 이런 빈도는 기대빈도보다 높다고 볼 수 있으며 이런 상황이 우연히 발생할 확률은 드물다. 이는 p값에 대한 연구자의 개입이 있었을 수 있음을 시사한다. 그리고 이런 패턴은 다른 연구들에서도 비슷하게 나타난다.
이러한 일들은 p-hacking 이라는 이름으로 학계에 알려져 있다. 연구자 측에서 유의한 값만 보고하고 p값을 인위적으로 통제하여 학술지에 보고하는 행위를 일컫는데 구체적으로 다음과 같은 방법들이 있다.
(1)집단의 크기가 충분히 커지면 p값이 0.05미만으로 작아지므로(이론적으로 무한히 커지면 p값은 0에 수렴한다) 최대한 많은 데이터를 수집하여 분석에 이용한다.
(2)데이터 수집 중간중간 지속적으로 통계분석을 시도하고 p가 0.05미만으로 나타나는 순간 수집을 멈춘다.
(3)데이터 분석을 할 때 한가지 분석방법으로 통계학적 유의성이 나타나지 않는다면 다른 통계학적 방법을 이용하여 p값이 0.05미만으로 나타나는지 살펴본다.
(4)애초에 많은 변수들을 한꺼번에 조사하여 그 중 유의한 p값을 나타내는 것만을 제시한다.
이러한 p-hacking은 많은 문제점을 야기한다. p값으로 인해 잘못 해석된 주장이 받아들여져서 재현이 되지 않고 다른 사람들의 후속연구가 잘못된 방향으로 진행되어 자원낭비의 원인이 되기도 한다. 또한 영가설검증의 경우 주장의 근거로 p값을 내세우고 그 것에 대한 신뢰로 말미암아 연구가 논문이 되는 것인데, 극단적으로 말해 누구나 p값을 hacking할 수 있다면 논문과 신문사설의 차이점이 없다고 할 수도 있는 것이다. 그러다 보니 p값의 임계점을 0.05가 아닌 0.005로 낮추자는 주장도 나오고(3) p값의 사용을 금지하는 저널이 나타나기도 하였으며(4), 단순 상관관계를 해석하기보단 인과관계를 해석하기 위한 모델(causal inference)에 대해 많은 연구들이 진행되고 있다.
연구자로서는 p값에 대한 의존도를 낮추고 베이지안 추론(Bayesian inference) 등의 대안적 방법의 도입을 확대하여 진리에 더 다가가는 자세가 필요하다. 또한 단순히 p값만 제시하는 것이 아니라 효과크기 등을 기술하는 것이 좋다. 그리고 데이터를 분석할 때 어떤 변수를 수집하고 어떤 방법으로 분석을 할지 미리 정한 후 결과에 따라 바뀌지 않아야 하며 샘플사이즈도 연구 시작 전 미리 적절한 설명력을 가질 수 있게 설계되어야 한다. 데이터 처리과정까지 blind로 진행하는 Triple-blind trial 또한 많은 연구자들이 실행하고 있는 방법 중 하나이다.
논문을 peer review하는 입장에서는 가능하면 raw data에 대한 공개권한을 확보하고 p값 외에 효과크기 등의 다양한 parameter들을 검증하는 것이 필요하고 publication bias를 막기 위해 유의하지 않은 결과더라도 그것이 의미 있는 결과이고 연구 방법론상 문제가 없다면 출판을 고려하는 것이 바람직할 것이다.
p-hacking 을 연구부정으로까지 보는 것에 대해서는 사람마다 의견이 다를 수 있으나, 과학윤리의 중요한 부분 중 하나로 심각한 문제로 받아들여지고 있는 추세이며 근절되지 않고 있다. 이러한 점으로 인해 미국 통계학회는 2019년 3월 학회지를 p-hacking으로 관련한 내용들로만 출간하였다(5). 최근 데이터의 크기가 커지고 다루는 방법들이 다양하고 고도화되면서 오히려 점점 더 이러한 p-hacking 이 쉬워지는 추세로 보이기도 한다. 그러니 우리는 논문을 쓰는 연구자로서, 혹은 논문을 읽는 독자로서 최소한 현대의 많은 의학/사회과학/보건학 등의 논문에서 p<0.05 라는 것만으로 논문이 주장하는 가설을 명징한 진실로 받아들이는 것은 피해야 한다. 단순히 p<0.05라는 것은 많으면 5%까지는 우연히 그 결과가 나올 수 있다는 뜻이며 이러한 통계적 오류의 가능성을 꼭 감안하여 논문의 결과를 비판적으로 받아들이는 자세가 필요하다.
- Ref)
- 1. https://normaldeviate.wordpress.com/2012/08/16/p-values-gone-wild-and-multiscale-madness/
- 2. Head, M. L., Holman, L., Lanfear, R., Kahn, A. T., & Jennions, M. D. (2015). The Extent and Consequences of P-Hacking in Science. PLoS Biology, 13(3): e1002106.
- 3. Ioannidis JPA. The Proposal to Lower P Value Thresholds to .005. JAMA. 2018;319(14):1429–1430. doi:10.1001/jama.2018.1536
- 4. David Trafimow & Michael Marks (2015) Editorial, Basic and Applied Social Psychology, 37:1, 1-2, DOI: 10.1080/01973533.2015.1012991
- 5. https://www.tandfonline.com/toc/utas20/73/sup1?nav=tocList