



인공지능 기술과 언어치료
 0
한국과학기술연구원 AI·로봇연구소 지능로봇연구단
0
한국과학기술연구원 AI·로봇연구소 지능로봇연구단
한양대학교 의과대학 HY-KIST 바이오융합학과
임윤섭
임윤섭 박사는 Boston University의 System Neuroscience 분야에서 박사과정을 마치고 2014년부터 한국과학기술연구원 AI로봇연구소에서 책임연구원으로 근무하고 있습니다. 지능로봇 기술에서부터 인간-로봇 상호작용을 위한 다양한 연구를 수행 중이며, 2020년부터는 한양대학교 바이오융합학과에서 청각인지 분야를 연구하고 있습니다.

21세기 들어 기계학습, 딥러닝, 로봇과 같은 인공지능 기술의 성능이 고도화되고, 인간 생활의 다양한 분야에서 최신 기술들을 적극적으로 활용하고자 하는 시도들이 많아지고 있습니다. 예를 들어 인간보다 뛰어난 체스, 바둑 실력을 가진 인공지능 에이전트가 개발되고, 생활 필수품이 된 자동차가 스스로 원하는 곳으로 운전을 할 수 있게 되는 등 이전에는 상상에서만 가능했던 일들이 우리의 눈 앞에서 펼쳐지고 있습니다. 일상생활에서 뿐만 아니라 심지어는 의료현장에서도 인공지능 기술이 적용되어서 의료 영상 데이터로부터 질병을 판단하는 기술, 병원에서의 검체 및 물건 배송 업무를 도와주는 로봇과 같은 기술들이 활용되고 있습니다. 이번 기고문에서는 우리의 생활에 이와 같이 밀접하게 다가온 인공지능이라는 어떻게 보면 꽤 어려워 보이는 연구 분야의 개념을 먼저 설명하고, 언어치료를 위해 사용될 수 있는 인공지능 기술들을 소개하도록 하겠습니다.
인공지능은 무엇일까요? 위키피디아에 쓰여진 정의는 아래와 같습니다.
Artificial intelligence (AI) is intelligence demonstrated by machines, unlike the natural intelligence displayed by humans and animals, which involves consciousness and emotionality.
인공지능은 인간이나 동물이 아닌 인공적으로 만들어진 “기계를 통해 나타나는 지능” 이라고 합니다. 다시 말해, 인공지능을 가졌다는 뜻은 어떠한 상황 또는 경험에 대해서 컴퓨터, 로봇과 같은 기계들이 인식 또는 판단을 할 수 있는 능력을 갖게 된다는 것을 의미합니다. 실제 이 분야는 전통적인 AI와 기계학습의 분야로 나누어지며 그 세부적인 연구 내용에서도 꽤 많은 차이를 갖고 있습니다. 그러나 이러한 구분을 고려하지 않고 기계학습 분야의 내용 중심으로 설명하겠습니다.
기계가 지능적인 판단을 하기 위해서는 입력되는 데이터가 갖고 있는 특징을 구분할 수 있어야 합니다. 이러한 능력을 부여하는 기계학습 방식에는 비지도학습(Unsupervised Learning)과 지도학습(Supervised Learning)으로 나누어집니다. 비지도 학습 방법을 이용하면 주어진 데이터의 특징에 따라 데이터를 그룹화할 수 있습니다. 예를 들어 다양한 환자들의 증상 데이터가 있고 이러한 증상에서 나타나는 비슷한 패턴들을 그룹화하는 용도로 사용 가능합니다. 그에 반해 지도학습 방법을 이용하면, 데이터의 입출력 관계를 학습하게 되며, 이렇게 학습된 모델을 통해 환자의 증상에 따른 질병 진단과 같은 일에 적용 가능합니다. 기계학습의 방법은 매우 다양하며, 적용하고자 하는 목표에 따라 비지도 또는 지도 학습을 수행하고, 많은 경우의 연구에서 하나의 방법만으로 자신이 분석하고자 하는 데이터를 처리하지는 않습니다. 데이터의 특징에 따라서 성능이 더 좋은 방법들이 항상 있기 때문에 다양한 방법을 적용하고 더 좋은 결과를 나타내는 방법으로 기계학습을 이용한 분석을 수행합니다.
다양한 기계학습 방법 중에서 최근에 가장 많이 주목을 받는 방법은 신경망 기술입니다. 신경망은 실제 뇌를 구성하는 신경에서의 학습 방법을 모사한 방식으로 널리 알려져 있습니다. 신경의 수상돌기(Dendrite)로 들어오는 다수의 입력 정보가 처리되고 축색돌기(Axon) 끝을 통해 출력 정보가 나가는 과정으로 하나의 단위신경이 모델링 됩니다. 신경망은 여러 개의 단위 신경이 포함되며, 다수의 노드와 계층으로 구성하여 보다 복잡한 데이터를 처리하는데 사용합니다. 최근에는 더 깊은 구조를 가진 딥러닝(Deep Learning) 이라는 방법이 많이 활용되고 있습니다. 이러한 기법을 이용하기 위해서는 매우 많은 양의 학습 데이터가 필요하며, 지난 10여년간 다양한 분야의 학습 데이터들과 기존의 기계학습 방법으로 학습된 모델의 성능을 뛰어넘는 딥러닝 방법들이 제안되어 오고 있습니다.
언어치료를 위한 연구에서도 기계학습의 방법이 활용되는 분야는 매우 많으며, 그 중에서 문자형태의 단어를 벡터로 표현하여 언어의 의미를 파악하기 위해서 사용되는 기법, 문장을 입력으로 받아서 음성으로 바꾸는 기술 그리고 로봇 및 스마트기기 앱을 활용한 언어치료 응용 기술에 대해서 소개해 드리겠습니다. 먼저 아래에 쓰여 있는 2개의 문장을 한 번 보겠습니다. 하나는 서울쥐와 시골쥐라는 동화에서 나오는 문장이며, 다른 하나는 블로그에 쓰여진 컴퓨터 마우스에 관한 리뷰입니다.
그런데 시골쥐가 달콤한 빵을 한 입을 베어 문 순간 고양이의 울음 소리가 들렸어요. 서울쥐는 시골쥐의 손을 잡아 끌어 고양이를 피했어요.
동화, 서울쥐와 시골쥐
마우스 커서 움직이는 것도 잘되고, 클릭도 잘 되는데 휠을 상하로 움직여도 화면 스크롤이 되지 않았다.
컴퓨터 마우스 블로그 리뷰
이 글을 읽으면 동화에서 어떠한 일들이 벌어지고 있는지, 마우스 사용자가 어떠한 일을 겪었는지 머리 속으로 상상이 가능합니다. 다시 말해, 하나의 문장을 구성하는 동사, 명사, 부사 등의 단어가 갖는 의미를 알고, 글쓴이가 처한 상황이 갖는 의미 또한 파악이 되었다는 뜻입니다. 그렇다면 우리가 이러한 문장을 기계 또는 컴퓨터로 하여금 인식 작업을 수행시킨다고 생각해 봅시다. 각 문장을 구성하는 문자들을 어떠한 방식으로 표현해야 기계가 쓰여진 문장을 인식 또는 이해할 수 있을까요?
| 방식 | Model | Year | 설명 |
|---|---|---|---|
| 빈도기반 | HAL | 1996 | Word-by-word matrix |
| LSA | 1997 | Word-by-document matrix, SVD | |
| Topic Models | 2007 | Word-by-document matrix, LDA | |
| 예측기반 | Word2vec | 2013 | Neural network model |
| GloVe | 2014 | Predict words’ probability of co-occurrence |
위 표에 나열된 5가지 방식이 현재 자연어처리 분야에서 가장 대표적으로 단어를 숫자로 이루어진 벡터로 표현하는 방법들입니다. 이러한 방법들은 모두 “비슷한 의미를 가진 단어는 비슷한 문맥에서 사용된다.” 라는 가정하에 특별한 과정을 거쳐 각 단어가 가지는 의미를 숫자로 이루어진 벡터의 형태로 표현하게 됩니다. 빈도에 기반한 방법은 특정 단어가 문장 내에서 어떠한 단어와 같이 나타나는 빈도의 패턴으로 단어를 나타내어 줍니다.
| Patient | Hospital | Medicine | Physician | Doctor | |
|---|---|---|---|---|---|
| Physician | 4 | 5 | 3 | 0 | 0 |
| Doctor | 10 | 10 | 7 | 0 | 0 |
예를 들어 위 표와 같이 Physician과 Doctor라는 단어는 하나의 문장에서 동시에 나타나지는 않지만, 빈도의 패턴이 비슷한 것을 알 수 있습니다. 즉, 서로 비슷한 빈도의 패턴으로부터 두 단어가 갖는 의미가 비슷하다고 추정할 수 있습니다. 예측기반 방법은 신경망으로 모델링 되기도 하며, 빈도 방식의 모델보다 훨씬 더 그 성능이 좋은 것으로 알려져 있으며 최근에 가장 많이 사용되는 방식입니다.
그러나 많은 인지과학자들이 벡터기반의 단어 의미 표현 방식은 인간이 갖고 있는 의미 표현 방식을 반영하지 못한다고 생각했습니다. 가장 큰 이유는 어떠한 단어가 갖는 의미는 고정되어 있지 않고, 문맥에 따라 변화되기 때문입니다. 그런데 놀랍게도 벡터로 표현된 방식이 많은 경우에 사람이 갖는 의미표현과 유사할 수도 있다는 증거들이 실험적으로 발견되어 오고 있습니다. 서로 비슷한 의미를 갖는 단어들의 cluster내 벡터간 거리와 인간이 갖고 있는 word-association 정도와 상관관계가 높다는 것을 확인하였으며, 행동 실험을 통해서도 인간의 의미파악 행동(예: 반응속도)과 단어 의미 벡터 거리 사이에 유의미한 상관관계가 있음을 보여 주었습니다.
자녀들을 키우면서 어릴 때부터 독서가 많이 강조되고 있고, 언어 학습 및 치료에서도 대화식 책읽기가 효과가 높다는 것이 알려져 있다고 합니다. 그런데, 자녀들에게 시간을 내서 책을 읽어 주기가 너무 힘듭니다. 부모를 대신해서 책을 읽어주는 기술이 있다면 얼마나 좋을까요? 그리고, 만약에 언어치료를 수행하는 과정에서 기계가 대신 책을 읽어 준다면, 책 읽기 과정에서 나타나는 환자들의 반응을 언어 치료사가 보다 쉽게 관찰 할 수 있을 것입니다. 이러한 수요를 반영했는지, 최근에 인공지능 기기를 활용한 동화책 읽어주는 서비스가 나타나고 있습니다. 개발된 기기들은 부모 목소리로 동화책을 읽어주거나, 카메라를 통해 글자를 인식하고 동화를 읽어주는 서비스도 제공된다고 합니다. 이러한 서비스에서 갖추어야 할 가장 핵심 기술은 TTS, 즉 Text-To-Speech 기술입니다. TTS와 관련된 여러 기술들이 있지만 그 중에서 가장 흥미를 끄는 기술은 목소리를 복제하는 Voice Cloning 기술입니다. 복제된 목소리를 만들기 위해서는 다수의 발화 문장을 녹음한 뒤, 긴 시간 동안 학습을 거친 뒤에 입력된 목소리 데이터에 대한 인공지능 모델이 완성됩니다. 다수의 데이터와 학습 시간이 필요하지만 꽤 높은 수준의 TTS 모델을 학습할 수 있는 기술들이 제안되어 오고 있으며, 저 또한 제 목소리를 수집하여 제 대신 여러 문장을 말해 줄 수 있는 모델을 만들어 보기도 하였습니다.
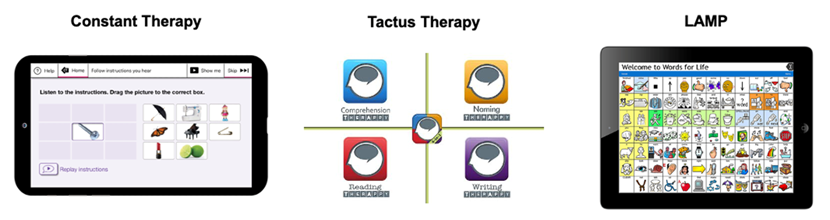
언어치료 및 진단을 위한 다양한 스마트 기기들이 개발되어 오고 있으며, 위 사진은 대표적인 스마트기기인 태블릿 컴퓨터에서 활용할 수 있는 언어치료용 앱입니다. 왼쪽에서부터 Constant Therapy, Tactus Therapy, LAMP 입니다. Constant therapy는 보스턴 대학교의 언어치료 연구자들이 창업한 회사의 제품이며, 뇌졸증, 치매 환자들의 언어 치료에 활용되고, Tactus는 뇌졸증으로 인한 실어증(Aphasia) 환자 치료 그리고 LAMP는 자폐아동의 언어치료에 활용된다고 합니다. 한국과학기술연구원에서는 이화여대 언어병리학과와의 협력을 통해 로봇을 활용한 언어인지 치료 기술 개발하고 있습니다. 이화여대에서는 2015년도에 노년층의 문장 이해정도를 평가할 수 있는 “문장-그림 일치 과제 형식”의 문장 이해 검사 방법을 제시하였습니다. 이러한 결과를 바탕으로 해당 검사를 웹에서 사용할 수 있는 형태로 제작하였으며, 로봇과의 상호작용을 통해 문장이해 능력 평가를 수행하는 시스템을 개발해 오고 있습니다. 아직 실험실 수준에서 그 기능을 확인하는 정도이지만, 개발된 시스템이 기존에 개발된 연필과 종이 기반의 테스트와 비슷한 성능을 가질 수 있는지, 실제 노인들이 사용하는데 있어서는 무리가 없는지 등등을 검증할 예정입니다.
1976년도에 출간된 아이작 아시모프의 Bicentenial man이라는 소설에는 앤드류라는 휴머노이드 로봇이 등장합니다. 이 로봇은 청소, 요리 등 어려운 집안 일부터 시작하여 사람과 매우 능숙하게 대화할 수 있는 인공지능 로봇으로 기술되어 있습니다. 아직까지도 현실은 인간과 비슷한 지능과 행동을 가진 로봇과 인공지능 시스템을 개발하기에는 넘어야 할 산들이 많습니다. 다양한 기계학습 방법, 로봇 응용 기술들이 더 많이 연구되고 활용하는 실험이 많아지면 이러한 모습을 언젠가는 볼 수 있을 것이며, 언어 치료의 분야에서도 인공지능의 기술이 폭 넓게 활용될 수 있으리라 기대합니다.