



“인공지능? 머신러닝? 빅데이터? 알쏭달쏭한 개념 쉽게 다가가기”
 0
한림대학교 이비인후과,
0
한림대학교 이비인후과,
한림대학교 의료인공지능센터
김동규

2016년 알파고의 등장 이후 이제 우리 주변에서 너무 쉽게 인공 지능과 관련한 이야기가 끊임없이 들려오는 시대에 우린 살고 있습니다. 가깝게는 인공지능 스피커, 인공지능 세탁기, 인공지능 청소기 등등 여러 생활가전제품에 인공지능이라는 이름이 붙어 있으며, 우리의 삶의 터전인 의료 현장에서도 인공지능으로 암을 진단하고, CT&MRI를 판독하고, 심지어 인공지능으로 코로나 진단까지 할 수 있는 시대입니다. 이처럼 우리는 가히 “인공지능의 홍수”시대에 살고 있다고 말할 수 있습니다. 그러나 과연 인공지능, 머신러닝, 빅데이터 비슷하지만 다른, 또, 다른 듯 하지만 비슷한 이들 개념에 대해서 우리가 얼마나 명확히 이해하고 있는지에 대해 의문이 생기는 것 역시 사실입니다. 지금 이 글을 읽으시는 이비인후과 선생님들 중에서도 인공지능에 대하여 매우 잘 알고 계신 분들도 계실 것이고 전혀 문외한인 분들도 계실 것입니다. 서두에 말씀드리지만 이 글은 순전히 인공지능에 대해서 코드 컴맹이 이해할 수 있는 난이도로 인공지능과 머신러닝 그리고 빅데이터 각각의 의미와 차이점 그리고 활용법을 알려드리고자 하는 것을 목적으로 합니다.
먼저 필자가 어떻게 인공지능을 연구하고 랩을 꾸리게 되었는지 말씀드리고자 합니다. 필자는 지금 소속 대학의 의료인공지능센터에 소속되어 있고 2020년 5월에 생긴(아직 1년도 되지 않은 신설랩) 필자 개인의 인공지능랩에는 3명의 대학원과정 학생과 4대의 학습용 GPU 서버가 있는 풋내기 인공지능 연구자입니다. 올해 갑자기 찾아온 COVID-19 여파로 임상진료 부담이 현저히 줄어들고 대외 활동이 완벽히 사라지면서, 생긴 많은 여유 시간을 잘 활용한 덕에 부족하지만 개인 인공지능랩을 시작할 수 있게 되었습니다. 필자는 약 3~4년 전부터는 R 프로그램을 활용한 건강보험공단 코호트 기반 연구논문을 10여편 작성하였는데 이때 R 프로그램을 처음 익히면서 틈틈히 파이썬(Python) 프로그램을 익혀왔고, 올해 초 1월 한달 동안 대학에서 허락한 빅데이터 인재 양성 교육과정에 참여하면서(진료를 약 한달가량 쉬었음) 본격적으로 심화학습을 할 수 있는 기회가 있었고 이를 잘 활용한 것이 지금의 작지만 소중한 랩을 가지게 된 것 같습니다. 그리고 지금은 Polysomnography auto-sleep scoring, PNS CT reading 등의 알고리즘 개발연구 및 GAN 테크닉을 이용하여 Neck CT non-enhance 이미지를 Neck CT enhance 이미지로 Reconstruction 하는 연구를 진행하고 있습니다.
이야기를 다시 본론으로 돌아와서, 인공 지능(artificial intelligence)이라는 개념은 1956년 존 매카시 교수가 처음으로 사용했으며 당시 개념은 인텔리젼트한 기계를 만드는 공학이라는 뜻이었습니다. 인공지능 연구는 최근 몇 년 사이 폭발적으로 성장하고 있으며, 2015년 이후 신속하고 강력한 병렬 처리 성능을 제공하는 GPU의 도입으로 더욱 가속화되고 있습니다. 또한, 갈수록 폭발적으로 늘어나고 있는 저장 용량과 이미지, 텍스트, 매핑 데이터 등 모든 영역의 ‘빅데이터’ 시대 역시 인공지능 연구의 성장세에 큰 영향을 미쳤습니다. 머신러닝(machine learning)이라는 용어는 1998년 톰 미첼 교수가 “작업에서 경험을 통해 성능이 향상되는 기계 혹은 컴퓨터의 학습”이라고 정의했습니다. 즉, 인공지능은 가장 넓은 개념이고 인공지능의 중요한 구현 방법 중 하나가 머신러닝입니다. 그러므로 머신 러닝은 기본적으로 알고리즘을 이용해 데이터를 분석하고, 분석을 통해 학습하며, 학습한 내용을 기반으로 판단이나 예측을 합니다. 그리하여 궁극적으로 의사결정 기준에 대한 구체적인 지침을 소프트웨어에 직접 코딩해서 넣는 것이 아닌 대량의 데이터와 알고리즘을 통해 컴퓨터 그 자체를 학습시켜 작업 수행방법을 익히는 것을 목표로 합니다. 우리가 흔히 사용하는 이메일에서 스팸메일을 자동으로 걸러주는 기능이 바로 머신러닝을 이용한 경우입니다. 그리고 오늘날 머신러닝 영역에서 많이 사용되는 알고리즘이 바로 인공신경망(artificial neural network)입니다. 이는 특정정보를 첫번째 레이어에 입력하면 그 뉴런들은 정보를 다음 레이어로 전달하는 과정을 마지막 레이어에서 최종 출력이 생성될 때까지 반복하는 알고리즘입니다. 이 과정에서 각 뉴런에는 수행하는 작업을 기준으로 입력의 정확도를 나타내는 가중치가 할당되며, 가중치를 모두 합산해서 최종 출력이 결정됩니다. 딥러닝(deep learning)은 이러한 인공신경망의 한 형태로 기존의 인공신경망이 복잡한 문제를 해결하기 위해 신경망의 층수를 여러 층 쌓는 경우 학습과정에서 데이터가 사라져 학습이 잘되지 않는 현상 및 학습한 내용은 잘 처리하나 새로운 사실을 추론하는 것을 잘 못하는 두가지 한계를 극복하기 위해 만들어진 새로운 방법론입니다.
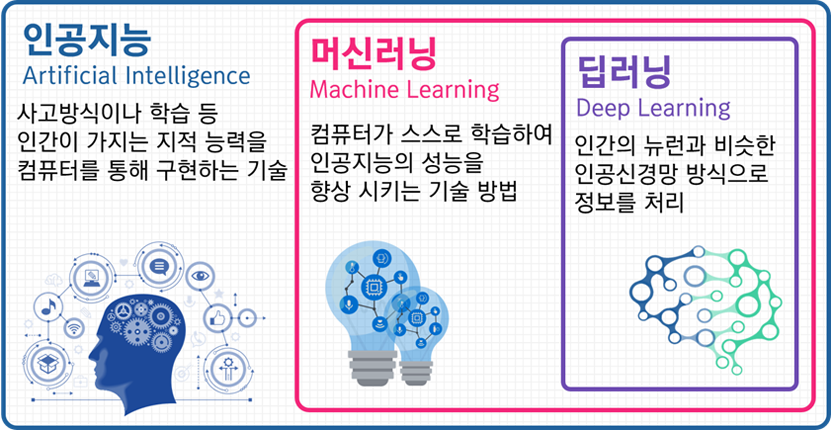
즉, 인공지능 > 머신러닝 > 인공신경망 > 딥러닝의 관계가 성립하는 것입니다. 조금 더 설명하자면 대표적인 딥러닝의 모델은 CNN (convolutional neural network)와 RNN (recurrent neural network)가 있습니다. CNN은 주로 이미지를 인식하는데 사용됩니다. 우리가 CT, MRI, X-ray, 안저촬영 등을 이용해 특정 질환을 인공지능으로 자동판독하는 경우 대부분 CNN 모델을 기반으로 만들어집니다. 반면에 RNN은 음성과 글자 등 순차적인 정보를 인식하는데 주로 사용됩니다. 따라서 RNN은 음성인식, 기계번역, 이미지 설명 등 여러 곳에서 활용되며, CNN과 RNN을 combination하여 의료분야에서 sequential한 의료데이터의 인공지능 연구에 활용하기도 합니다.
한편, 빅데이터(big data)는 단순히 어마어마하게 많은 데이터를 의미하는 것이 아닙니다. 기본적으로 크기(volume), 다양성(variety), 속도(velocity)라는 3요소를 갖추고 있는 데이터를 빅데이터라고 이야기 할 수 있습니다. 여기서 크기는 데이터의 양을 말하는 것이고, 다양성은 데이터의 형태의 유무와 연산 가능 여부에 따라 나누어지는 특징, 속도는 빠르게 분석하고 처리할 수 있는 능력을 의미합니다. 이러한 데이터의 특성으로 인해 빅데이터는 이를 잘 활용할 수 있는 플랫폼의 존재가 필수적입니다. 진료에 활용되는 데이터와 임상연구 데이터, 국가적 차원에서 관리되는 공공기관 데이터, 의료기기를 통해 수집되는 기기 기반 데이터, 분자 수준에서 수집된 오믹스 데이터, 개인의 일상생활을 통해 수집되는 라이프로그 데이터, 앱·소셜 미디어 데이터 등이 보건의료 빅데이터에 포함됩니다. 그리고 이러한 빅데이터에서 의미를 도출하기 위해 적용되는

다양한 분석 기술 중 오늘날 가장 각광받는 것이 바로 인공지능 기술입니다. 특히, 인공지능은 특정한 프로그램에 의존하는 것이 아니라 데이터로부터 스스로 학습하는 것이 핵심이 되는 만큼, 인공지능 자체의 기술력도 중요하지만 양질의 데이터를 확보하고 많은 양의 데이터를 분석하는 빅데이터와 떼려야 뗄 수 없는 관계에 있습니다. 따라서 인공지능 연구에 있어서 양질의 데이터와 데이터의 양이 매우 중요한 요소로 작용하며, 이러한 데이터 수집 및 전처리 과정에 따라 개발될 인공지능 기반 서비스/솔루션의 성능이 좌지우지되는 것이라고 이해할 수 있습니다.
Garbage in, garbage out (GIGO)이라는 말을 있습니다. 이는 "쓰레기가 들어가면 쓰레기가 나온다"는 뜻으로 컴퓨터 과학분야에서 컴퓨터가 논리 프로세스에 의해 운영되기 때문에 결함이 있는, 심지어는 터무니없는 입력 데이터(쓰레기가 들어감)라도 의심을 품지 않고 처리하며, 생각하지도 않던 터무니없는 출력(쓰레기가 나옴)을 만들어낸다는 사실을 지칭합니다. 그러므로 제가 생각하는 앞으로의 우리의 모습은 의료진들이 직접 인공지능 알고리즘을 코딩하는 것이 아니라 정확한 데이터를 확보하는 것이 인공지능 시대의 경쟁력이자 핵심역량이 될 것이라 생각합니다. 이상으로 부족한 글을 마치겠습니다. 모쪼록 과거 저처럼 인공지능 문맹이셨던 분들에게 재미난 설명과 소개가 되었기를 바랍니다. 부족한 글 끝까지 읽어주셔서 감사합니다.



