



R로 하는 통계 분석 바로 시작하기
 1000
건양대학교병원 김한태
1000
건양대학교병원 김한태

임상 데이터를 바탕으로 한 학술 발표나 논문을 준비할 때 가장 먼저 찾아오는 걱정 중 하나는 통계 분석입니다. 임상 연구 주제를 받아 처음 연구를 시작하는 전공의나 펠로우 선생님들이 특히 그러할 것으로 생각됩니다. 좀더 현실적으로 말해보자면, 단순히 평균을 구하고 그래프를 그리는 것은 엑셀이나 파워포인트, 혹은 다른 도구로 어떻게 할 수 있다고 해도, 통계적 유의성, 즉 P-value를 어떻게 뽑아낼 지가 막막할 수 밖에 없습니다.
통계 소프트웨어를 사용하여 이러한 통계적 유의성을 찾게 되는데요, 임상의들에게서 그동안 가장 널리 사용되었던 것은 SPSS입니다. 저도 마찬가지였습니다. 아무래도 프로그램을 실행시켰을 때의 전반적인 형태가 우리에게 익숙한 엑셀과 비슷하고, 별도의 코드 입력 없이 클릭만으로 필요한 수준의 분석이 가능하기 때문이죠. 다만 무료 프로그램이 아니기 때문에, 직접 구독을 하거나 소속된 기관에서 라이선스를 구매해야만 사용이 가능합니다. 소속기관에서 라이선스를 제공해도 원내에서만 사용이 가능하다는 점, 혹은 사용할 때마다 대여를 해야 하는 등 여러 제약이 있습니다. 개인이 직접 구독하는 경우는, 아무래도 사용 빈도에 비해 그 가격이 그리 만만하지는 않아서 부담스럽고요.
SPSS나 SAS 등의 통계 프로그램의 사용에 많은 비용이 든다는 점은 사실 꽤 오래전부터 지적되던 문제였습니다. 전문적으로 통계를 공부하고 연구하는 대학에서도 이 라이선스 비용을 감당하기가 어려운 수준에 이르렀는지라, 그 대안을 찾고자 하였고 이때 프로그래밍 언어의 일종인 R이 주목 받기 시작했습니다. 우리나라에서는 대략 2000년대 중반부터 각 대학의 통계학과에서 R의 사용이 점차 늘어나기 시작했습니다. R은 완전히 무료, 오픈소스 프로그램입니다. 그러나 흔히 잘 알고 있는 C, C++와 같은 컴퓨터 프로그래밍 언어의 형태로 되어 있기 때문에 금방 배워서 사용하기가 조금 어렵습니다. 저희처럼 이러한 컴퓨터 언어가 낯선 의사들에게는 어렵다는 말도 사실 나오지 않고요, 뭔가 좀 막막하고 답답해요.
앞서 언급한 SPSS의 불편한 점(기관이 구독하더라도 원내만 사용 가능하고 때때로 대여 형태를 취해야 하는 점), 그리고 개인적으로 주로 사용하는 노트북을 윈도우에서 맥OS를 사용하는 맥북으로 바꾸게 되면서 SPSS를 사용하기가 조금 불편해졌습니다. 따라서 R을 논문 작성 등을 위한 통계분석의 도구로 사용하기 시작했고 이 글은 이에 대한 경험을 나누고자 하는 것입니다. R 통계에 대한 많은 책 앞부분에서 많이 다루게 되는 변수의 개념들에 대한 것은 과감하게 생략하고, 가지고 계신 데이터(엑셀파일)로 바로 시작해볼 수 있도록 말씀드리고자 합니다.
1. 설치할 프로그램
R 프로그램 언어 자체를 먼저 설치해야 합니다. 이는 https://www.r-project.org 사이트에서 다운 받을 수 있으며, 각각 컴퓨터 환경(윈도우 혹은 맥OS)에 맞게 다운 받아 설치하면 됩니다. 별다른 설정 없이 일반적으로 프로그램을 설치하는 것과 동일하게 해주시면 됩니다. R을 설치한 다음, RStudio라고 하는 프로그램을 함께 설치합니다(https://posit.co/downloads/ RStudio가 최근 회사명을 posit으로 바꾸었습니다). 실제 통계분석은 R을 실행해서 하지 않고 RStudio 프로그램으로 하는 편이 훨씬 편합니다. 설치 방법은 검색창에 ‘R 설치’, ‘R studio 설치’ 이렇게 치면 자세히 많이 나오기 때문에 그걸 참고하셔도 됩니다. 어쨌든 이 두가지를 모두 설치하고, 이제 RStudio를 실행시키면 아래와 같은 형태가 됩니다.

그림 1. RStudio 실행화면.
2. 데이터(엑셀) 파일의 준비.
사실 실제 통계분석에서 가장 중요한 것은 바로 이 단계입니다. 말 그대로, 엑셀 파일 정리하는 것을 말합니다. 이 단계에서는 통계적 지식 당연히 필요 없고요, 그냥 열심히 해야 합니다. 다시 한번 강조하지만, 이 단계가 사실은 가장 중요해요. 2022년 3월 웹진에 저희 학교 김종엽 교수님께서 이 주제로 써주신 글이 있습니다(“통계 분석을 염두에 둔 엑셀 파일 만들기”). 이 글을 참고해서 데이터를 잘 정리만 해두면 제가 앞으로 보여드릴 것은 사실 아무것도 아닙니다. 저는 예시를 위해서 500명의 각 주파수별 순음청력검사 결과와 어음명료도 검사의 결과를 정리한 데이터를 활용하고자 합니다.
한가지 주의사항은 원(raw) 데이터인 엑셀파일은 파일명과 내용에 한글은 가능한 사용하지 않는 것이 좋습니다. 또한 파일명도 띄어쓰기 없이 해주세요. 띄어쓰기가 필요할 때는 _를 활용할 수 있습니다.
3. 데이터 파일의 Import
잘 정리된 엑셀 파일을 RStudio 프로그램에 먼저 넣어야 합니다. 그림 1 화면의 우측 상부에 Import (  혹은
혹은  으로 보일 수도 있습니다)를 클릭하면 엑셀에서 파일 불러들이는 메뉴가 나옵니다(
으로 보일 수도 있습니다)를 클릭하면 엑셀에서 파일 불러들이는 메뉴가 나옵니다( ). 여길 클릭해서 엑셀 파일을 불러들이면 됩니다. 그냥 기본값으로 그대로 Import하셔도 무방합니다. 이 단계에서, readxl이라는 패키지를 설치하라는 말이 나올 수도 있습니다. 설치해주시면 됩니다. 파일명이 그대로 데이터의 이름으로 들어가게 됩니다.
). 여길 클릭해서 엑셀 파일을 불러들이면 됩니다. 그냥 기본값으로 그대로 Import하셔도 무방합니다. 이 단계에서, readxl이라는 패키지를 설치하라는 말이 나올 수도 있습니다. 설치해주시면 됩니다. 파일명이 그대로 데이터의 이름으로 들어가게 됩니다.

그림 2. 엑셀파일을 불러들였을 때 화면.
(1)은 데이터셋의 이름(‘PTA_sample’), (2)는 불러들인 데이터(단지 보여주기만 할 뿐 여기서 값을 수정하거나 고칠 수는 없습니다.), (3) 명령어를 입력하는 창. (1)의 PTA_sample이라는 데이터셋을 R에서는 ‘데이터프레임’이라고 부릅니다.
4. 데이터 분석해보기
이제 바로 분석을 할 수 있습니다. 먼저 그냥 우측 귀의 어음명료도의 평균을 구해보죠. 우측 귀의 어음명료도는 PTA_sample이라는 데이터프레임 안에 Rt_SDS로 코딩이 되어있습니다. 이를 R의 언어로 표현하면 PTA_sample$Rt_SDS라고 합니다. 평균에 해당하는 함수에 넣어주면 되죠. 평균의 함수가 mean이거든요, mean (PTA_sample$Rt_SDS)라고 입력하면 됩니다.

다 이런 식입니다. 표준편차도 마찬가지에요. 표준편차의 함수가 sd이니까 아래로 입력하면 계산됩니다.

분석할 때 많이 해보는 상관분석도 한번 해보겠습니다. Rt_SDS와 Rt_AC_1000 (1000 Hz에서의 기도청력역치)의 상관관계를 구하고 상관변수도 한번 보겠습니다. 음의 상관성이 있을 것이라고 예측되기는 하죠. cor.test라는 함수에 보고자 하는 변수 2개를 그냥 넣으면 됩니다.

그림 3. Rt_SDS와 Rt_AC_1000의 상관분석.
P value는 2.2e-16이하로 P<0.001임을 의미하고 상관계수는 -0.7027021로 계산되네요. 음의 상관관계가 뚜렷합니다.
5. 데이터 다루기
500, 1000, 2000, 4000 Hz에서의 기도청력 평균을 구하려면 어떻게 하면 될까요? 직관적으로 할 수 있고 아래와 같이 입력하면 됩니다. PTA_sample안에 Rt_AC_mean이라는 변수를 만들고 그 안에 이 식에서 지정한 방식으로 계산해서 넣으라는 의미입니다. 위는 4분법 계산이고 아래는 6분법 계산입니다.

다만 데이터를 꼭 이렇게 다루지는 않아도 된다고 말씀드리고 싶습니다. 이러한 계산은 엑셀에서도 다 할 수 있는 부분이거든요. 엑셀에서 계산을 해서 넣고 그 엑셀파일을 다시 Import하면 그만입니다. 데이터의 갯수가 많을 때는 가능한 R 내에서 처리를 해야겠지만, 임상자료와 같이 N수가 그리 많지 않은 자료를 다룰 때는 엑셀에서 데이터처리를 하면서 전체 데이터의 형태를 보면서 하는 것이 오히려 도움이 될 때도 많습니다.
6. 논문의 Table 1 만들기
R의 장점이 함수패키지가 매우 많다는 점인데요, 오늘 볼 것은 이런 패키지 중 moonBook이라는 패키지를 사용해보려고 합니다. 가톨릭대학교 성빈센트병원 순환기내과의 문건웅 교수님께서 만드는 패키지로 흔히 논문의 Table 1에 들어갈 법한 표에 해당하는 분석을 한번에 해결할 수 있습니다. 다만 패키지의 설치가 필요하고 이는 아래와 같이 합니다.

그림 4. moonBook 패키지 설치.
install.packages (“moonBook”)이라고 입력하면 아래 메세지가 뜨면서 설치가 됩니다. 이 package를 사용한다고 컴퓨터에 알려줘야 합니다. library(moonBook)이라는 명령어를 입력하면 이 패키지를 사용한다는 의미로 보시면 됩니다.
잠깐 package설치와 library에 대해 설명을 드리자면, 수술실 수술도구를 예시로 생각하면 좋을 것 같습니다. package를 설치하는 것은 수술도구를 구매하는 것이라고 보시면 됩니다. 그 도구가 필요 없는 수술을 할 때는 그냥 어디 수술실 한 곳에 두죠. 그런데 수술 중 그 도구가 필요할 때 술자가 요청을 하면 꺼내서 사용할 수 있게 준비를 해주죠. 이렇게 비치된 도구를 사용을 위해 준비시켜주는 것을 library로 이해하시면 됩니다.
설치 및 library로 로딩을 마쳤으면 한번 아래와 같이 입력을 해보겠습니다.

결과의 의미는 바로 이해가 되실겁니다. 연령(Age), 좌측 귀의 SDS(Lt_SDS), 우측 귀의 SDS(Rt_SDS), 좌측 1000 Hz에서 기도청력역치(Lt_AC_1000), 우측 귀 1000 Hz에서 기도청력역치(Rt_AC_1000)의 성별에 따른 차이를 볼 수 있습니다. 통계적 유의성(P-value)도 한번에 계산됩니다.
그리고 아래의 형태로 입력하면 모든 변수에서 성별에 따른 차이를 모두 계산해줍니다. 보려고 하는 변수명 대신 .을 찍으면 데이터프레임에 포함된 모든 변수를 성별에 따른 차이로 구분해줍니다.

논문에서 그룹간 비교를 주된 목적으로 한다면, 성별 대신 지정한 그룹을 넣어주면 되겠죠. 이 테이블을 쉽게 만들면서 연구 결과의 전반적인 경향성을 간단하게 확인할 수 있습니다. 이 데이터에서는 대체로 고주파 영역에서 남성이 청력소실의 크기가 더 크다고 볼 수 있겠네요.
7. ChatGPT 활용하기
ChatGPT 많이 들어보셨을 것으로 압니다. 인공지능 챗봇인데요, 그 기능이 놀라운 수준이라 현재 전세계적인 관심을 받고 있습니다. 이 ChatGPT가 R 코드도 짜줍니다! 심지어 데이트프레임의 이름과 변수명을 정확히 지정해주면 그것에 딱 맞게 짜줄 정도입니다. 아래를 보시면 됩니다. 제가 이렇게 물어봤습니다. “Hi. I would like to make codes for R. The name of the dataframe is 'PTA_sample'. And the name of variable is 'Rt_SDS' in the dataframe. How can I get the mean value of 'Rt_SDS'?”
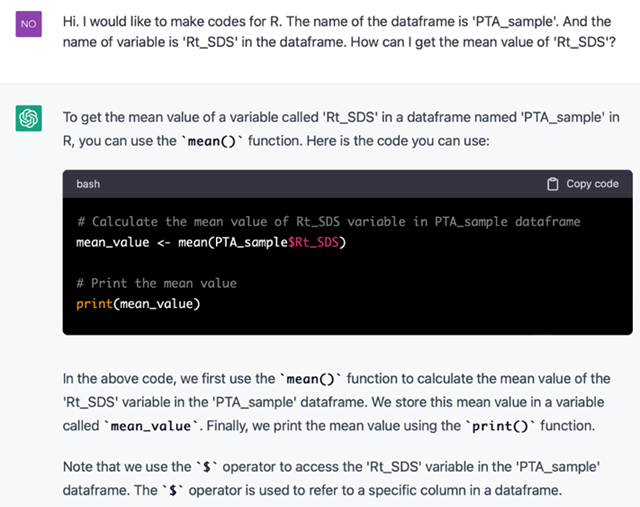
그림 5. ChatGPT에게 평균 구하는 R 코드를 요청한 화면
제가 앞에서 보여드렸던 mean(PTA_sample$Rt_SDS) 명령어를 보여주고 이를 mean_value라는 변수안에 넣어주었네요. 나름의 설명도 제공을 해줍니다.
지금까지 R로 하는 통계 분석을 바로 시작할 수 있는 방법들에 대해 말씀을 드렸습니다. 본 글은 일단 R을 이용해서 작은 분석이라도 한번 해볼 수 있는 것을 목적으로 하기 때문에 많은 내용을 과감히 생략하였음을 양해 부탁드립니다. 저도 처음에는 책을 보며 차근차근 공부를 했었는데요, 기초적인 기반을 닦는 과정에 아무래도 많은 시간이 소요되다보니 금방 책을 놓게 되었습니다. 이번에 말씀드린 것처럼, 일단 부딪히며 시작한 뒤, 그 다음에 책을 다시 보니 더 이해가 쉬웠습니다. R의 전체적인 분위기에 익숙해진 다음에 한번 책을 보시며 차근차근 공부해보는 것도 좋을 것 같고, 이에 본 글이 조금이나마 도움이 될 수 있다면 큰 기쁨이 될 것 같습니다.